|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
| patrikey: А вот интересно, Rapid Gap может быть отрицательным? |
что-то пока не пойму, что за цифры они рисуют
известно, что с увеличением контроля вдвое, прибавка в силе примерно плюс 55-60 Эло
для рапида (понижение контроля в 4 раза, с 120 до 30 мин) падение силы составляет 110-120 Эло
для блица (понижение контроля в 24 раза, с 120 до 5 мин) падение 250-270 Эло |
|
|
| номер сообщения: 150-27-20604 |
|
|
|
|
| падение силы составляет 110-120 Эло |
это в среднем
ну хорошо, посчитаем мы индивидуальное падение, для кого-то оно будет 90, для кого-то 140, но это другие цифры чем нарисованы у них |
|
|
| номер сообщения: 150-27-20605 |
|
|
|
|
Ukrfan: | patrikey: А вот интересно, Rapid Gap может быть отрицательным? |
По определению - делается предположение, что качество и стабильность игры падает от классики к рапиду, и от рапида к блицу - не может. Вам никак не может мешать запас времени. Если для вас 30 минут на партию достаточно, играйте ее за 30 минут. |
Умница наш Ukrfan - написать самоочевидные вещи и на всякий случай не ответить на прямой вопрос.
Gap не может быть отрицательным, точно так же как дисперсия и ско.
На результирующий рейтинг оказывает влияние не только разница в рейтинге, но и разница в Gap. Последняя, возрастая, будет серьезно смягчать потерю (прибавку) в рейтинге в случае, например, односторонней игры.
Поэтому, например, играя в рапид или блиц с Карякиным или Непомнящим, с которыми у него полная корреляция, Карлсен рискует бОльшим рейтингом (и Gap соответственно), чем с Каруаной. |
|
|
| номер сообщения: 150-27-20606 |
|
|
|
|
| Дело в том, что рейтинг в сочетании с зазором определяе силу игры в соответствующем формате.Пожтому, естественно, играя в блиц с Каруаной, сила которого в этом формате соответствует 2685, Карлсен (со своими 2798) рискует потерять гораздо больше (а приобрести гораздо меньше), чем играя против Непо с его 2726. Как результат партии может повлиять на зазор, мы пока не знаем. |
|
|
| номер сообщения: 150-27-20607 |
|
|
|
|
Jeweller: | patrikey: А вот интересно, Rapid Gap может быть отрицательным? |
что-то пока не пойму, что за цифры они рисуют
известно, что с увеличением контроля вдвое, прибавка в силе примерно плюс 55-60 Эло
для рапида (понижение контроля в 4 раза, с 120 до 30 мин) падение силы составляет 110-120 Эло
для блица (понижение контроля в 24 раза, с 120 до 5 мин) падение 250-270 Эло |
1. Здесь многое непонятно: например как определяется gap, если шахматист (имеющий рейтинг ФИДЕ) никогда не играл турниры по быстрым шахматам или блицу с обсчетом ФИДЕ (или они обсчитывают какие то дополнительные турниры?).
2. И тенденция заниженного рейтинга у знакомых (  ) шахматистов-любителей также выглядит сомнительно. ) шахматистов-любителей также выглядит сомнительно.
3. Но, главная проблема: я не могу самостоятельно посчитать свой рейтинг, а должен довериться "этой компании"  . . |
|
|
| номер сообщения: 150-27-20548 |
|
|
|
|
| FIBM:главная проблема: я не могу самостоятельно посчитать свой рейтинг, а должен довериться "этой компании" . |
Вы никому ничего не должны. Просто гордо игнорируйте GCT - сами придут, и сами предложат вам участие... |
|
|
| номер сообщения: 150-27-20549 |
|
|
|
|
Весьма поучительно "погружаться") в различные разделы, например этот:

Там, в середине раздела, среди прочего, открываются вот какие "красоты":
 |
|
|
| номер сообщения: 150-27-20550 |
|
|
|
|
Jacob08:
Там, в середине раздела, среди прочего, открываются вот какие "красоты":
|
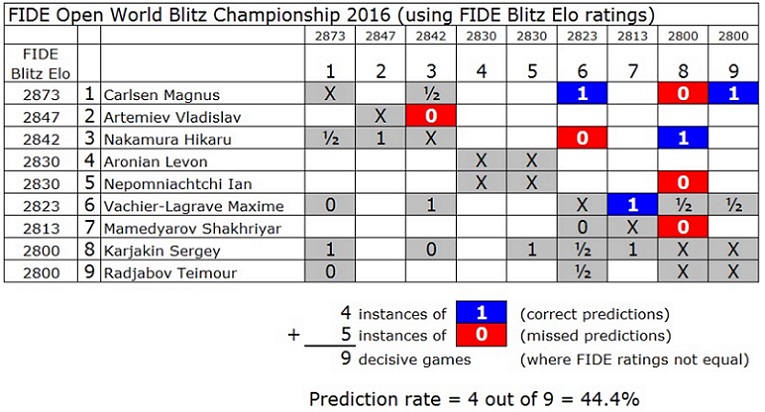
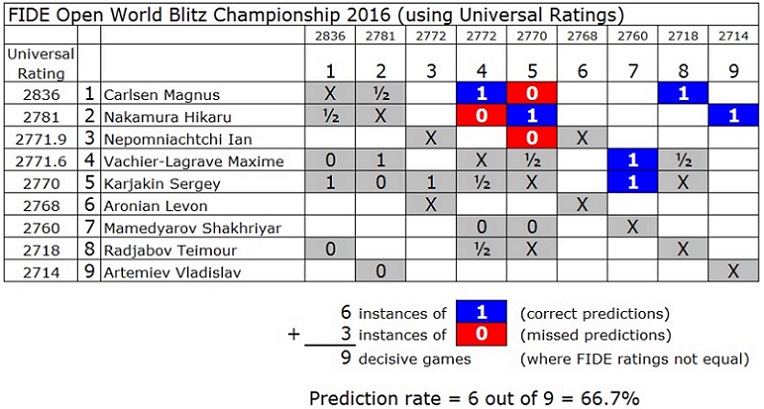
Интересно, что различия в данном примере статистически не значимы (например, по Fisher's exact test), и авторы не могут этого не знать.
У авторов есть и более многочисленные примеры. самый практически важный, ИМХО, - предсказания результатов игроков за 2600 в классику в 2013-2016гг. Утверждается, что новая система лучше. Но разница - всего 0.56 процента. Статистический анализ показывает, что значимой разницы для этих игроков нет, по крайней мере на выборке такого размера (4269 результативных партий). И это при том, что новый алгоритм оптимизировался на данных 2013-2015 гг.
В целом, авторы немного хитрят, проводя свои сравнения. Во-первых, они не учитывают ничьи. Поэтому их улучшение прогноза на примерно 1 процент (даже менее, для классических игр) на самом деле оказывается ещё меньше. Во-вторых, они используют сложную систему расчётов, в которой включение быстрых игр является лишь одним элементом. При этом, весь свой небольшой успех они списывают именно на комбинированный обсчёт, а не, например, на ограничение влияния старых игр на рейтинг. Я не удивлюсь, если именно последний фактор играет решающую роль в чуть-чуть улучшенном прогнозе, а комбинация игровых форматов только портит картину. Во-всяком случае, опровержения такой гипотезы в представленных данных я пока не вижу.
ПС А не созрела ли это дискуссия для переноса в отдельную тему? |
|
|
| номер сообщения: 150-27-20551 |
|
|
|
|
Ахахах, что я заметил!  

__________________________
Trump won. Lets grab some pussy. |
|
|
| номер сообщения: 150-27-20552 |
|
|
|
|
Что-то с этими зазорами не то. Не может быть, чтобы Карлсен "играл блиц с такой силой, как игрок с рейтингом 2798 в классику". При таком определении и зазор в 500 очков был бы недостаточен. Дело наверняка в чем-то другом.
Разумеется, сама идея объединить три разные игры в одной системе рейтинга абсурдна. |
|
|
| номер сообщения: 150-27-20553 |
|
|
|
|
Ukrfan: | FIBM:главная проблема: я не могу самостоятельно посчитать свой рейтинг, а должен довериться "этой компании" . |
Вы никому ничего не должны. Просто гордо игнорируйте GCT - сами придут, и сами предложат вам участие... |
Не говорите ерунду. Причем здесь GCT, если авторы "Универсального рейтинга" позиционируют свою систему как систему лучшую чем система ФИДЕ для любителей (и посчитали всех любителей). |
|
|
| номер сообщения: 150-27-20554 |
|
|
|
|
PapaKarlo: Во-вторых, они используют сложную систему расчётов, в которой включение быстрых игр является лишь одним элементом. При этом, весь свой небольшой успех они списывают именно на комбинированный обсчёт, а не, например, на ограничение влияния старых игр на рейтинг. Я не удивлюсь, если именно последний фактор играет решающую роль в чуть-чуть улучшенном прогнозе, а комбинация игровых форматов только портит картину. Во-всяком случае, опровержения такой гипотезы в представленных данных я пока не вижу.
|
+100. Есть много шахматистов просто НЕ играющих в рапид и блиц с обсчетом, но утверждается, что их УР позволяет предсказывать классику лучше чем стандартный ЭЛО. Совершенно очевидно с чем это улучшение связано. |
|
|
| номер сообщения: 150-27-20555 |
|
|
|
|
Jeweller: Есть еще один резерв усиления - базовая формула обсчета.
Как показал чемпионат моделей несколько лет назад, модель Эло не самая лучшая. В частности, базовая не модифицированная модель Сонаса показывала лучший результат, а уж модифицированный модели Эло, Сонаса и другие, тем более.
Что используется в этом проекте неизвестно, но что-то подсказывает что все та же модель Арпада Эло. И это не самый плохой вариант (модель Эло не плоха), есть модели хуже. |
Ничего похожего на Эло там нет. | URS™ involves a time-weighted regularized maximum likelihood calculation |
Проще говоря, у них есть модель результата шахматной партии в зависимости от набора параметров (главные из которых - скиллы игроков), которая выражена функцией плотности вероятности. Они составляют огромное произведение из этих плотностей и наблюдаемых результатов партий (перемножают миллионы таких пар - по одной на партию). Это и есть "likelihood". Пары эти взвешены в зависимости от давности партии - это "time-weighted". Дальше с помощью одного из специальных алгоритмов находят набор параметров, который даёт наибольшую величину функции правдоподобия, т.е. наилучшим образом подходит. Это и есть "maximum". Из получившегося набора достают скиллы=рейтинги и показывают нам. Слово "regularized" должно означать, что они используют специальный трюк для обнуления малозначимых параметров, чтобы они не мешались.
Neofelis: Возникли такие вопросы:
1. Каким образом взвешивались разные форматы?
2. Что символизирует 1 очко рейтинга?
3. Как рейтинг коррелирует с вероятностью победы? |
На эти вопросы ответ будет только когда увидим научную бумагу, а не рекламу. Ну, возможно, по п.2 они старались сделать так, чтобы из разности рейтингов можно было вычислить ожидаемый результат по фидешной формуле.
| PapaKarlo:Интересно, что различия в данном примере статистически не значимы (например, по Fisher's exact test), и авторы не могут этого не знать. |
Не только знают, но и честно написали несколько раз про это.
| PapaKarlo:Утверждается, что новая система лучше. Но разница - всего 0.56 процента. |
| PapaKarlo:В целом, авторы немного хитрят, проводя свои сравнения. Во-первых, они не учитывают ничьи. Поэтому их улучшение прогноза на примерно 1 процент (даже менее, для классических игр) на самом деле оказывается ещё меньше. Во-вторых, они используют сложную систему расчётов, в которой включение быстрых игр является лишь одним элементом. При этом, весь свой небольшой успех они списывают именно на комбинированный обсчёт, а не, например, на ограничение влияния старых игр на рейтинг. Я не удивлюсь, если именно последний фактор играет решающую роль в чуть-чуть улучшенном прогнозе, а комбинация игровых форматов только портит картину. Во-всяком случае, опровержения такой гипотезы в представленных данных я пока не вижу. |
Они сильно улучшили алгоритм в целом (по сравнению с ФИДЕ), за счёт чего, я уверен, заметно улучшилась предсказательная сила. Но они этим не воспользовались по причине, как мне думается, упёртости кого-то (вероятно, Каспарова), выдвинувшего абсурдную идею получения универсального рейтинга. Грубо говоря, что Каспаров сказал, то Гликман и сделал, несмотря на то, что это выглядит бредом. Клиент платит деньги, значит он прав. Не случайно для экспериментальной проверки системы наняли статистика Ришара. Он, наверное, и написал этот раздел про проверку. Гликман и Сонас не захотели пачкаться. ;)
Cчитали бы классику, рапид и блиц раздельно, но по новому алгоритму, и цифры были бы более впечатляющими.
Причём, возможно, что рейтинги в рапид и блиц могли бы взять полезную информацию от классических партий, но наоборот - менее вероятно.
Конечно, всё зависит от количества партий. Скажем, если сыграна только 1 партия в классику и зато 100 в блиц, то, конечно, классический рейтинг от блиц партий может взять много информации. Но, скажем, если партий уже 10 в классику и 10 в блиц, то 10, сыгранных в блиц, - это больше шум, чем полезная информация.
__________________________
Trump won. Lets grab some pussy. |
|
|
| номер сообщения: 150-27-20556 |
|
|
|
|
| PapaKarlo:При этом, весь свой небольшой успех они списывают именно на комбинированный обсчёт, а не, например, на ограничение влияния старых игр на рейтинг. |
Органичение влияния старых игр, разумеется, есть и в Эло. Его правда, по мнению многих недостаточно (т.е, K=10 занижен), но оно есть.
__________________________
Trump won. Lets grab some pussy. |
|
|
| номер сообщения: 150-27-20557 |
|
|
|
|
Bulldozer:
Cчитали бы классику, рапид и блиц раздельно, но по новому алгоритму, и цифры были бы более впечатляющими.
Причём, возможно, что рейтинги в рапид и блиц могут взять информацию от классических партий, но наоборот - менее вероятно.
Конечно, всё зависит от количества партий. Скажем, если сыграна только 1 партия в классику и зато 100 в блиц, то, конечно, классический рейтинг от блиц партий может взять много информации. Но, скажем, если партий уже 10 в классику и 10 в блиц, то 10, сыгранных в блиц, - это, больше шум, чем полезная информация. |
Все проблемы, кроме женского характера, решаются с помощью понижающих коэффициентов. Если влияние результатов партий в блиц на основной кэф невелико, а остальная часть уходит в "зазор", то все не так глупо. |
|
|
| номер сообщения: 150-27-20558 |
|
|
|
|
Глупость даже не только в использовании блиц-партий с понижающим коэффициентом для классики. Да, это может быть искусственно введённым шумом, но если вес его маленький, то и фиг с ним - сильно не испортит. Ради чьей-то "великой" идеи URS™ можно терпеть. А в том, что в том же примере они по непонятной причине никак не используют эти зазоры для ранжирования перед блиц-турниром. И, видимо, не собираются использовать, ибо URS™. То есть, рейтинг официально один, а никакие не три.
__________________________
Trump won. Lets grab some pussy. |
|
|
| номер сообщения: 150-27-20559 |
|
|
|
|
Из того, что я пока прочел:
1) Они считают рейтинг-перфоманс сразу по всей больнице (то, что делалось в "Top GrandMasters Today"). Никаких предварительных рейтингов в этом способе не используется, это не то как традиционно считается перформанс в ФИДЕ-системе. Используется итерационный метод, когда за несколько итераций (последовательных пересчетов) значения рейтинг-перфомансов постепенно уточняются и стабилизируются с заданной точностью. Подход хороший - плюс.
2) Старые модели Эло, Сонаса или Гликмана не используются. Они сделали что-то другое. Вероятно, это не одна какая-то модель, а целый набор моделей (индивидуальных статистических гипотез). И в каждый конкретный момент (после каждого нового обсчета), используется(актуализируется) та из них, которая показала лучший результат при обсчете (меньшее отклонение рейтинг-перфомансов от показанных результатов). Если это так - второй плюс.
3) Используется не линейно-взвешенное затухание влияния старых результатов на перфомансы, а экспоненциальное. Глубина памяти 6 лет (72 месяца). Напомню, что традиционная система Эло также использует экспоненциальное затухание. Разница между двумя подходами в следующем. В традиционной Эло системе затухание есть функция партий - пересчет после каждой партии. У них это функция времени - уменьшение влияния старых результатов происходит по мере временного отдаления их настоящего времени. Нужно сказать, что разница между этими двумя подходами сводится к нулю, если шахматист играет равномерно во времени. И различия могут быть тем больше, чем неравномерней во времени играет шахматист. В модели Эло также может быть использована реализация затухания как функции времени, например я это в свое время делал, но не по экспоненциальному, а линейно-взвешенному варианту. Здесь авторам URS видимо тоже надо поставить плюс, затухание как функция времени по моему опыту лучше, а экспоненциальное затухание вместо линейно-взвешенного во многих случаях не хуже (часто лучше).
4) У них нет жесткого разделения на "классику", "рапид" и "блиц" при классификации контроля. Используются непрерывные функции, где контроль вычисляется как максимальное время,которое может быть потрачено на первые 60 ходов - это может быть, например, 150 мин, 120, 42, 41, 7 или 5. Вероятно отсюда берутся значения рапид и блиц "зазоров" для шахматистов, которые не играли с рапид и блиц контролями. Они экстраполируют зависимость, которая есть в диапазоне классического контроля, на рапид и блиц диапазон. Корректность такого подхода под вопросом (большим вопросом). Например, для многих случаев экстраполяция невозможна, т.к. шахматист играет с одним и тем же классическим контролем. В таком случае корректно определять его рейтинг и блиц "зазор" как неопределенный, а не рисовать какие-то средние по больнице цифры. Минус.
4а) Приводимые значение "зазоров" как величин снижения силы с укорочением контроля - абсурдны. Здесь минус с тремя вопросам ???
5) "Рапид" и Блиц" партии учитываются с меньшими весами. Какими не сказано. Приведу пример: не имея возможности отделять вручную короткие контроли в "Top GrandMasters Today", мне приходилось учитывать все, и иногда это приводило к уточнению - если партий в классику было мало или совсем мало, а иногда портило, вопиющий пример - учет рапид и блиц партий однажды сильно понизил перфоманс Широва. Здесь есть большой методологический вопрос - кроме того, что это "немного" разные шахматы, а блиц - "много" разные, у разных шахматистов разная мотивация. Например, партии в классику - максимальная, а блиц - нет. И смешивание всего в одну кучу может не дать уточнения, наоборот. По моему опыту - общий баланс все таки немного положительный, но(!) для некоторых шахматистов он сильно отрицательный. Конечно, если понижающие коэффициенты большие, например для рапида 1/4, для блица 1/24, то эти "шумы" много не испортят, но стоит ли допускать ради красивого слова "Универсальный рейтинг", возможное существенное искажение для отдельных персон? Вероятно полезен дополнительный фильтр для таких случаев.
__________
Пока мне кажется, что им удалось прилично увеличить точность самой модели, относительно модели Эло. |
|
|
| номер сообщения: 150-27-20560 |
|
|
|
|
Придумал новое развлечение - меряться зазорами. На какого игрока из первой 20-ки вы наиболее похожи? Скачайте CSV файл, если на сайте поиск вас не находит.
Я типа Ананд, а вы?
__________________________
Trump won. Lets grab some pussy. |
|
|
| номер сообщения: 150-27-20561 |
|
|
|
|
Jeweller: Из того, что я пока прочел:
1) Они считают рейтинг-перфоманс сразу по всей больнице (то, что делалось в "Top GrandMasters Today"). Никаких предварительных рейтингов в этом способе не используется, это не то как традиционно считается перформанс в ФИДЕ-системе. Используется итерационный метод, когда за несколько итераций (последовательных пересчетов) значения рейтинг-перфомансов постепенно уточняются и стабилизируются с заданной точностью. Подход хороший - плюс. |
По поводу этого метода последовательного приближения, по-моему, они писали не в том смысле, что это их метод, а том смысле, что существует такой метод.
В разделах "What is a Simultaneous Performance Rating?" и "Performance Ratings Explained" они описывают существующие методы, чтобы в дальнейшем было понятно, чем от них отличается их метод. Например, методы Сонаса (Chessmetrics) и Гликмана (US Chess) по данной классификации, видимо, являются Simultaneous Performance Rating with a Direct Formula (но термин мой - в тесте такого нет). И только в самом конце раздела "Performance Ratings Explained" они описывают их метод:
However, the URS™ took a more thorough approach.
...
Rather than inventing a specific formula that can be used to calculate ratings directly, like there is for the Elo system and for performance ratings, the URS™ involves a probability model that analyzes a large domain of possible ratings for each player, with some ratings being more likely than others (based upon the overall population distribution of chess strength). Across those possible ratings, our system then determines how likely the actual results would have been to occur, and ultimately determines the most likely overall set of ratings, for all players at once, in order to best explain the actual results.
| Jeweller:3) Используется не линейно-взвешенное затухание влияния старых результатов на перфомансы, а экспоненциальное. Глубина памяти 6 лет (72 месяца). Напомню, что традиционная система Эло также использует экспоненциальное затухание. Разница между двумя подходами в следующем. В традиционной Эло системе затухание есть функция партий - пересчет после каждой партии. У них это функция времени - уменьшение влияния старых результатов происходит по мере временного отдаления их настоящего времени. Нужно сказать, что разница между этими двумя подходами сводится к нулю, если шахматист играет равномерно во времени. И различия могут быть тем больше, чем неравномерней во времени играет шахматист. В модели Эло также может быть использована реализация затухания как функции времени, например я это в свое время делал, но не по экспоненциальному, а линейно-взвешенному варианту. Здесь авторам URS видимо тоже надо поставить плюс, затухание как функция времени по моему опыту лучше, а экспоненциальное затухание вместо линейно-взвешенного во многих случаях не хуже (часто лучше). |
По времени, наверное, лучше.
А вот интересно, этот коэффициент затухания у них есть свой на каждого игрока? И уточняет ли его основной алгоритм? Скорее всего, ответ "нет" и "нет", что жалко.
Интересный ещё вопрос, есть ли у них "зазоры" для белых/чёрных фигур.
| Jeweller:4) У них нет жесткого разделения на "классику", "рапид" и "блиц" при классификации контроля. Используются непрерывные функции, где контроль вычисляется как максимальное время,которое может быть потрачено на первые 60 ходов - это может быть, например, 150 мин, 120, 42, 41, 7 или 5. Вероятно отсюда берутся значения рапид и блиц "зазоров" для шахматистов, которые не играли с рапид и блиц контролями. Они экстраполируют зависимость, которая есть в диапазоне классического контроля, на рапид и блиц диапазон. Корректность такого подхода под вопросом (большим вопросом). Например, для многих случаев экстраполяция невозможна, т.к. шахматист играет с одним и тем же классическим контролем. В таком случае корректно определять его рейтинг и блиц "зазор" как неопределенный, а не рисовать какие-то средние по больнице цифры. Минус. |
А вот этого мы не знаем. Может, у них в модели существуют и уточняются СКО для зазоров, просто они не показаны. :)
| Jeweller:4а) Приводимые значение "зазоров" как величин снижения силы с укорочением контроля - абсурдны. Здесь минус с тремя вопросам ??? |
Не понял, почему абсурдны?
Upd: ага, прочитал ранее. Величина зазоров якобы мала. Да, действительно, выглядит так, что сильно мала. Мне тоже с самого начала так показалось. И навряд ли "глазомер" так сильно подводит.
| Jeweller:Конечно, если понижающие коэффициенты большие, например для рапида 1/4, для блица 1/24, то эти "шумы" много не испортят, но стоит ли допускать ради красивого слова "Универсальный рейтинг", возможное существенное искажение для отдельных персон? Вероятно полезен дополнительный фильтр для таких случаев. |
Да уж. Тут явно порылась какая-то политика или, скорее, маркетинг.
__________________________
Trump won. Lets grab some pussy. |
|
|
| номер сообщения: 150-27-20562 |
|
|
|
|
Bulldozer: | Jeweller:4а) Приводимые значение "зазоров" как величин снижения силы с укорочением контроля - абсурдны. Здесь минус с тремя вопросам ??? |
Не понял, почему абсурдны? |
Если "Gap" величина снижения силы при уменьшении контроля, то она должна быть в разы больше. |
|
|
| номер сообщения: 150-27-20563 |
|
|
|
|
| Bulldozer: А вот интересно, этот коэффициент затухания у них есть свой на каждого игрока? И уточняет ли его основной алгоритм? Скорее всего, ответ "нет" и "нет", что жалко. |
Идея хорошая, если сделали, тогда респект.
| Интересный ещё вопрос, есть ли у них "зазоры" для белых/чёрных фигур. |
Действительно, практической пользы от URS было бы гораздо больше, если бы вместо странных "Rapid Gap" и "Blitz Gap", сделали дополнительные "белый" и "черный" рейтинги. |
|
|
| номер сообщения: 150-27-20564 |
|
|
|
|
| Jeweller:Действительно, практической пользы от URS было бы гораздо больше, если бы вместо странных "Rapid Gap" и "Blitz Gap", сделали дополнительные "белый" и "черный" рейтинги. |
Не думаю, что больше. Для цвета можно брать какой-то стандартный поправочный коэффициент, потому что, согласитесь, специалистов белого (а тем более черного) цвета мы знаем намного меньше, чем акул блица. Навскидку приходит в голову Ананд, вероятно, есть еще, но вряд ли много.
Хотя, конечно, если бы еще и эта поправка была индивидуализирована, то предсказательная сила рейтинга еще повысилась бы... но, может быть, это премиум-вариант для платных подписчиков? |
|
|
| номер сообщения: 150-27-20565 |
|
|
|
|
| Ukrfan: Не думаю, что больше. Для цвета можно брать какой-то стандартный поправочный коэффициент |
Нет, стандартной поправкой не отделаться. Взгляните (данные старые (2010г), но суть не в этом):
Jeweller: Отношения реальности и стереотипов бывают подчас весьма причудливы, и делая «перфомансы по цветам», мне было интересно посмотреть, в частности, на «белых» Крамника, Топалова, Грищука, «черных» Раджабова, Мамедьярова, силу нынешнего «черного» Крамника..
Разница в силе белого и черного цвета по всем партиям за последние 52 недели представлена в таблице White – Black
Больше всего эта разница у Карякина – «белый» Карякин был сильнее «черного» на 78 пунктов
Для Грищука разница осталась традиционно большой
Серьезно сократилась она для Крамника – за счет того, что сила «черного» Крамника серьезно подтянулась к силе «белого»
«Белого» Крамника я ожидал увидеть в лидерах десятки белых перфомансов
Но предполагал, что черным цветом он пропустит вперед «черного» Карлсена и очень хорошего «черного» Ананда, однако результат виден в таблице «черной десятки» – Крамник лидер, черный цвет Крамника по сумме всех сыгранных партий за последние 52 недели сильнейший
«Черный» Раджабов ослаблен, несколько увеличилась разница между белым и черным цветом у Мамедьярова и Гашимова, «черные» Ананд и Пономарев по-прежнему сильны, сохраняют соотношение силы белого и черного цвета Аронян и Иванчук, Карлсен сбалансирован, «белый» Топалов ослаблен
Малахов, Ле Куанг Льем и Алмаши продемонстрировали практически такой же по силе черный цвет как и белый
Единственный из всех, «черный» Шорт сильнее «белого»
(значения в таблицах округлены до целых)
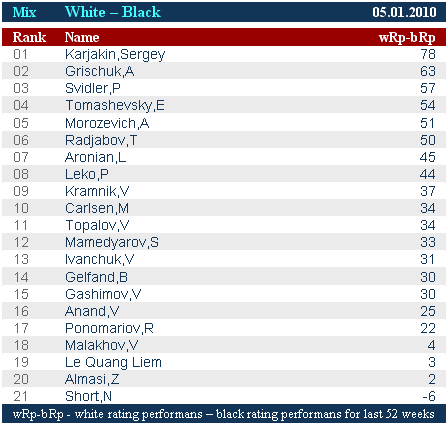 |
Jeweller: «Белый» и «черный» Крамник
5 «белых» восьмисотников
3 «черных» восьмисотника
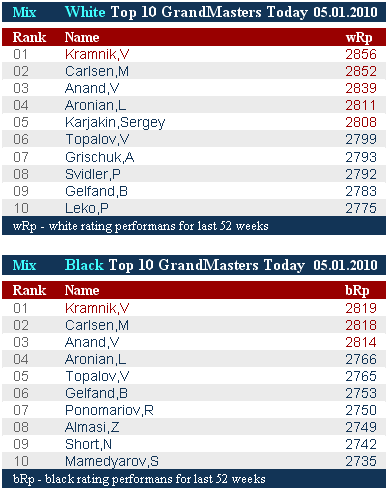 |
Jeweller: Интересны и такие цифры:
В среднем для первой десятки Микс-списка от 05.01 белый цвет сильнее черного на 42,6 пункта
Для второй - на 24,3 пункта
Для первой двадцатки в целом - на 33,4 пункта |
|
|
|
| номер сообщения: 150-27-20566 |
|
|
|
|
Странно это все, конечно.
Мировой рейтинг в то время возглавлял Карлсен, Крамник был 4м. У вас же Крамник возглавляет и белый, и чёрный рейтинги. Сомневаюсь в серьезной предсказательной силе этого метода.
Но это оффтоп - ситуация же с Анандом наводит на мысль, что просто "так сложилось" в том году. Трудно себе представить, чтобы человек за пару лет превратился из выраженно чёрного в общеизвестно белого... |
|
|
| номер сообщения: 150-27-20567 |
|
|
|
|
| Сорри, на вопрос первого абзаца вы уже тогда отвечали. Снимается. Но второй остаётся. |
|
|
| номер сообщения: 150-27-20568 |
|
|
|
|
| хорошо, удалил пост с повторным объяснением |
|
|
| номер сообщения: 150-27-20569 |
|
|
|
|
| Вы знаете, что я в перформансах не секу, но раз у знатоков зашла речь, то обидно было бы не напомнить о результатах прошлого года, представленных ntakos'ом (в хорошо известной Jeweller'у теме). |
|
|
| номер сообщения: 150-27-20570 |
|
|
|
|
Bulldozer: Jeweller: Из того, что я пока прочел:
1) Они считают рейтинг-перфоманс сразу по всей больнице (то, что делалось в "Top GrandMasters Today"). Никаких предварительных рейтингов в этом способе не используется, это не то как традиционно считается перформанс в ФИДЕ-системе. Используется итерационный метод, когда за несколько итераций (последовательных пересчетов) значения рейтинг-перфомансов постепенно уточняются и стабилизируются с заданной точностью. Подход хороший - плюс. |
По поводу этого метода последовательного приближения, по-моему, они писали не в том смысле, что это их метод, а том смысле, что существует такой метод.
В разделах "What is a Simultaneous Performance Rating?" и "Performance Ratings Explained" они описывают существующие методы, чтобы в дальнейшем было понятно, чем от них отличается их метод. Например, методы Сонаса (Chessmetrics) и Гликмана (US Chess) по данной классификации, видимо, являются Simultaneous Performance Rating with a Direct Formula (но термин мой - в тесте такого нет). И только в самом конце раздела "Performance Ratings Explained" они описывают их метод:
However, the URS™ took a more thorough approach.
...
Rather than inventing a specific formula that can be used to calculate ratings directly, like there is for the Elo system and for performance ratings, the URS™ involves a probability model that analyzes a large domain of possible ratings for each player, with some ratings being more likely than others (based upon the overall population distribution of chess strength). Across those possible ratings, our system then determines how likely the actual results would have been to occur, and ultimately determines the most likely overall set of ratings, for all players at once, in order to best explain the actual results.
|
Хорошо, что обратили внимание на эту тонкость. Никак не мог найти, где у них еще об этом написано.
Вкладка "About Us" -> "6. The URS™ Explained":
| The URS ™ considers the entire history of over-the-board games going back several years and iteratively calculates a "performance rating" simultaneously for all players in the rating pool. This yields a set of player ratings that best matches the observed results and is thus a better predictor for future game results. |
т.е:
| 1) Они считают рейтинг-перфоманс сразу по всей больнице ... Используется итерационный метод |
Ваше пояснение "Rather than inventing a specific formula" первому не противоречит, а дополняет, что и формулы изначально нет, и она тоже итерационно уточняется в ходе расчета. Это красиво, если так сделали. |
|
|
| номер сообщения: 150-27-20571 |
|
|
|
|
| Если честно, нихрена не понял в этой системе обсчета)). Пример: есть два шахматиста. У первого классический рейтинг ELO меньше на 11 пунктов, рейтинг в быстрых - выше на 28 пунктов, а в блице - выше на 51 пункт. Но при этом URS первого ниже на целых 62 пункта. |
|
|
| номер сообщения: 150-27-20572 |
|
|
|
|
| Alex_Dp: Если честно, нихрена не понял в этой системе обсчета)). Пример: есть два шахматиста. У первого классический рейтинг ELO меньше на 11 пунктов, рейтинг в быстрых - выше на 28 пунктов, а в блице - выше на 51 пункт. Но при этом URS первого ниже на целых 62 пункта. |
У кого-то результаты возможно весьма старые. А о ком речь ?
| Jacob08: Система работает с данными, основанными на результатах шахматистов строго за последние шесть лет (72 месяцев). Все данные для всех игроков при обновлении подвергаются обработке, причём "новые результаты" имеют больший вес в сравнении со "старыми результатами". Таким образом, например, оценка выдающегося результата несколько лет назад "по каплям" теряет свою "стоимость". |
Правда не знаю, "отмотали" ли они уже эти 6 лет назад - или это будет действовать лишь в будущем. |
|
|
| номер сообщения: 150-27-20573 |
|
|
| |
|
|
|
|
|
|
|
| Copyright chesspro.ru 2004-2025 гг. |
|
|
|